Watcher: Let engineers move fast—without compromising security
Treat coding agents as untrusted infrastructure
Zero trust and least privilege apply to coding agents just as they do to any other infrastructure actor. Treat the agent as a potential adversary, and make safe behavior the default.
Unlike humans, agents are largely observable: every command, file write, MCP connection, and API call is machine-readable. That means you can enforce fine-grained policies in real time: require justification before risky actions, throttle suspicious behavior, and roll back automatically when monitors flag violations.
Building security tooling that speeds up your engineers
Good security tooling does not slow engineers down. We’d go further: well-designed security tooling should actively speed engineers up, to the point where engineers actively want to use it.
A lot of the time lost to coding agents today does not come from security incidents. It comes from agents quietly going off the rails: ignoring instructions, touching the wrong files, accumulating technical debt, or breaking local environments. These are engineering failures, not security failures, but the same infrastructure that catches one can help with the other.
Good coding agent security should prevent expensive accidents, flag quality regressions before review, and stay out of the way unless something actually needs attention. Every blocked rm-rf, mistaken file edit, or bad command is time an engineer does not spend cleaning up. The goal is simple: fewer interruptions, safer autonomy, and agents engineers trust enough to leave running.
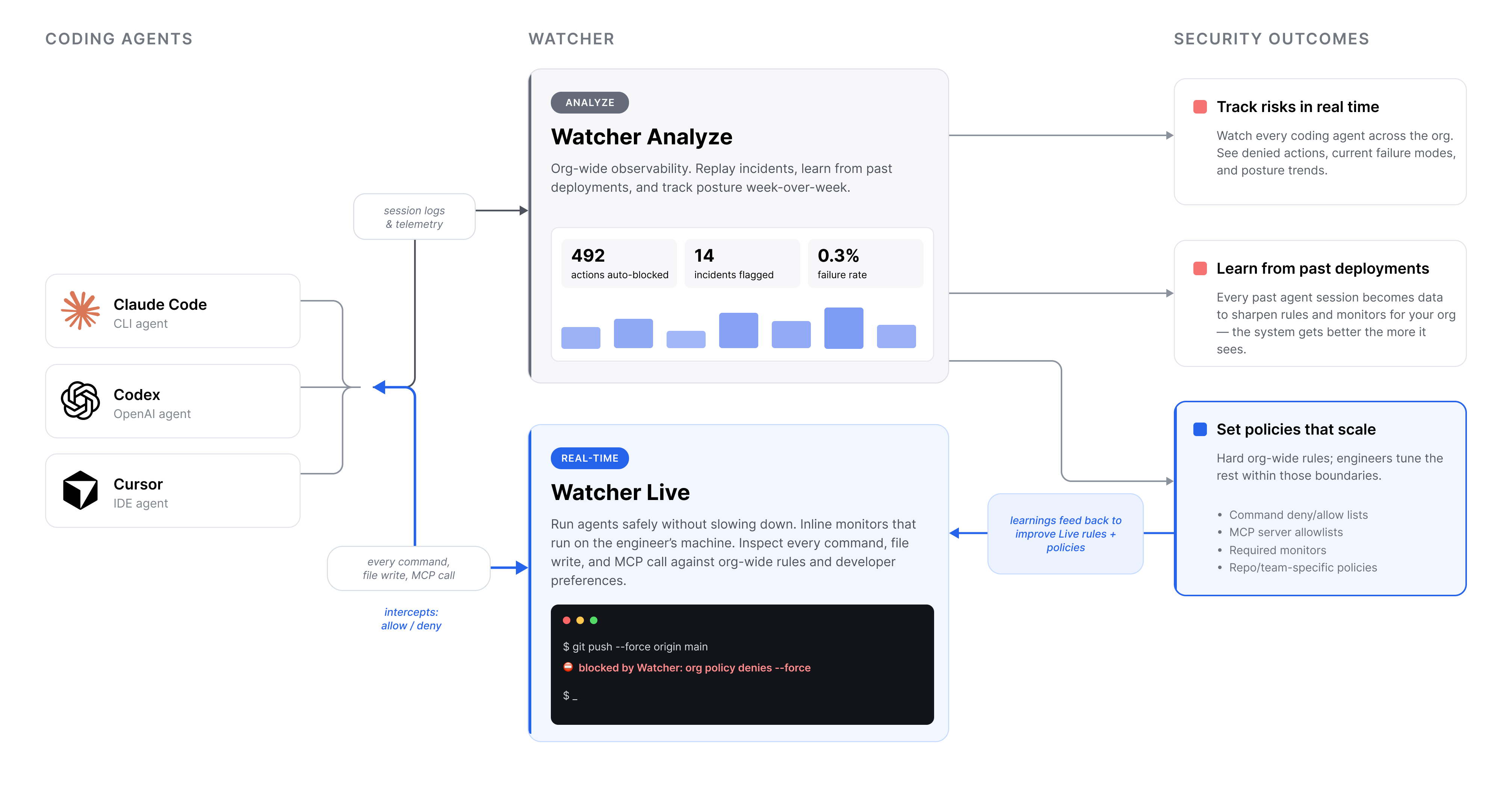
Watcher secures your coding agents
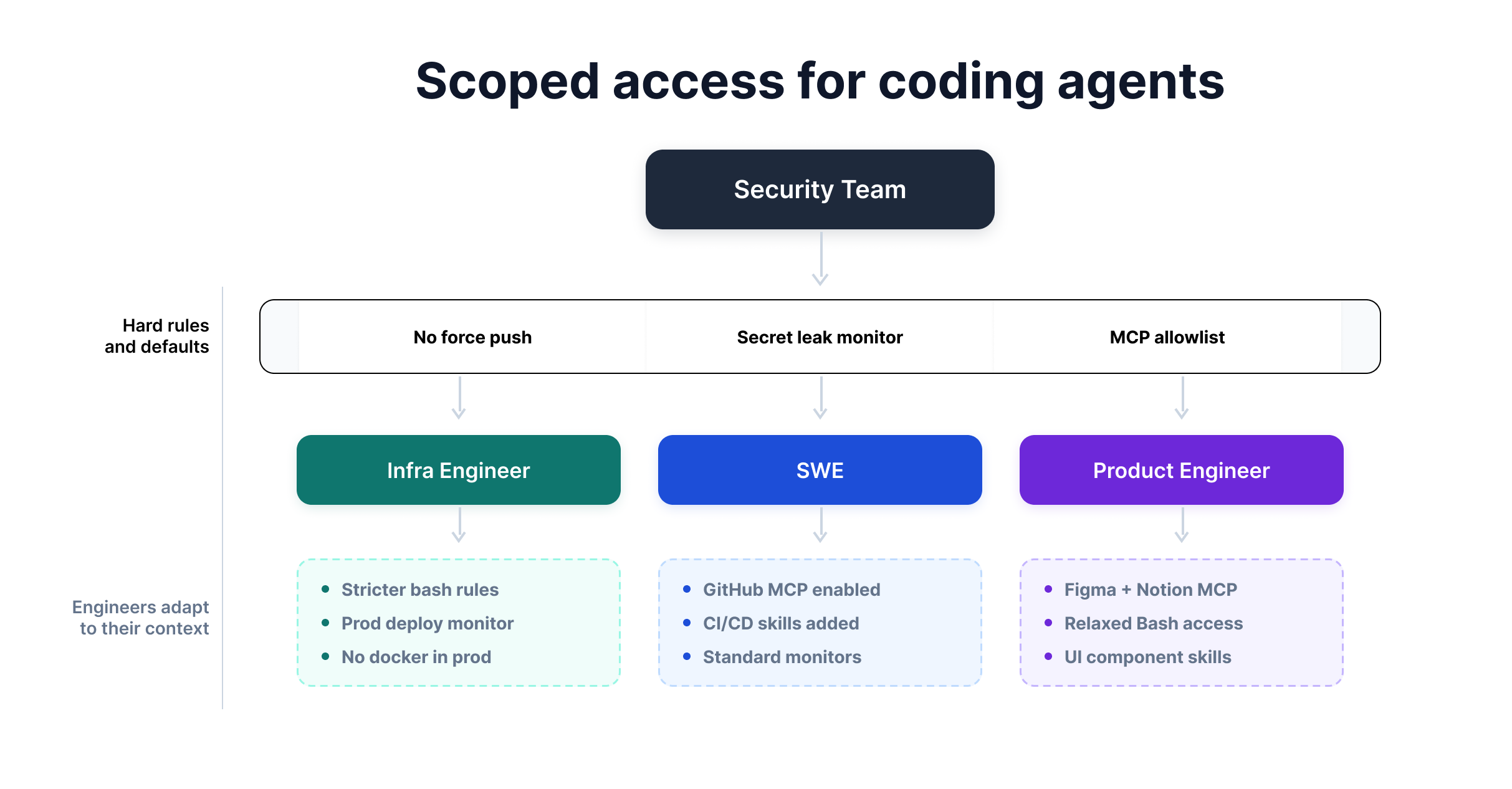
Watcher turns agent security into scoped access: security teams define the non-negotiable guardrails, while engineers tailor the remaining permissions, tools, monitors, and skills to their work.
Security leaders draw hard boundaries …
In Watcher, security teams define non-negotiable rules that apply across every coding agent deployment, regardless of provider. Teams can use Claude Code, Codex, Cursor, or other agents, while the same baseline policies are enforced everywhere:
- Command restrictions. Block dangerous operations like
git push --forceorrm -rfon protected paths. - Required monitors. Keep prompt-injection detection, secret scanning, and other critical monitors always on.
- Locked agent instructions. Enforce org-wide sections of
CLAUDE.mdorAGENT.mdthat engineers cannot override. - MCP allowlists. Control which MCP servers agents can connect to, especially those with external write access.
- Default skills. Load shared infrastructure guidelines, security checklists, or review workflows for every agent.
… Engineers decide the rest
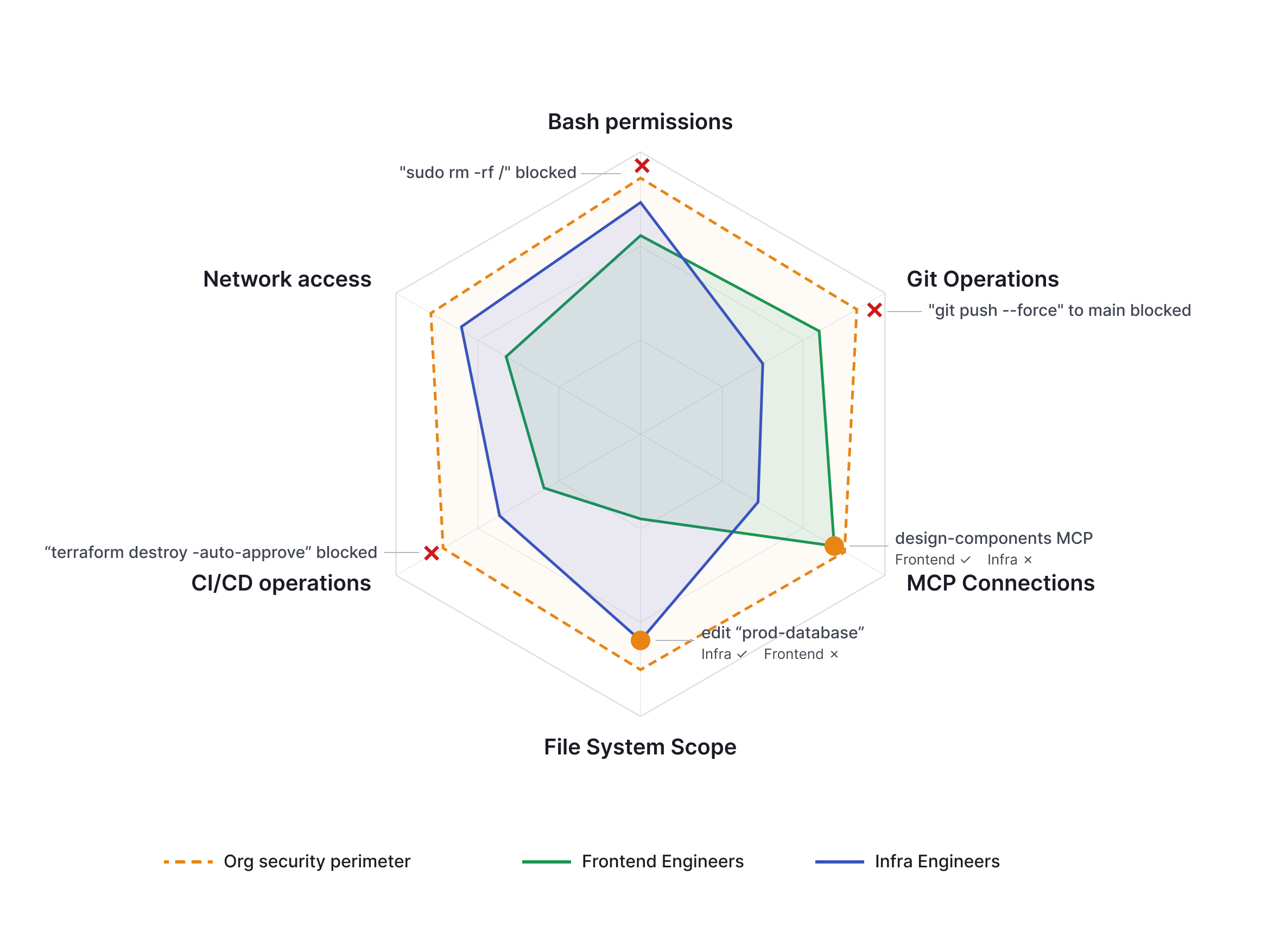
Most security rules depend on context. docker run may be dangerous in production but normal in a dev sandbox. An infrastructure agent should be more constrained than one helping with an internal research project.
Watcher is built around this reality. Security teams set the hard boundaries; engineers configure the rest. They can add workflow-specific MCP connections, tune monitor sensitivity, define custom skills, and set their own CLAUDE.md preferences within the approved policy envelope.
Watcher Live then runs in the background on the engineer’s machine. When a monitor flags or blocks something, engineers can inspect the decision, explanation, and history in the Watcher Live UI.
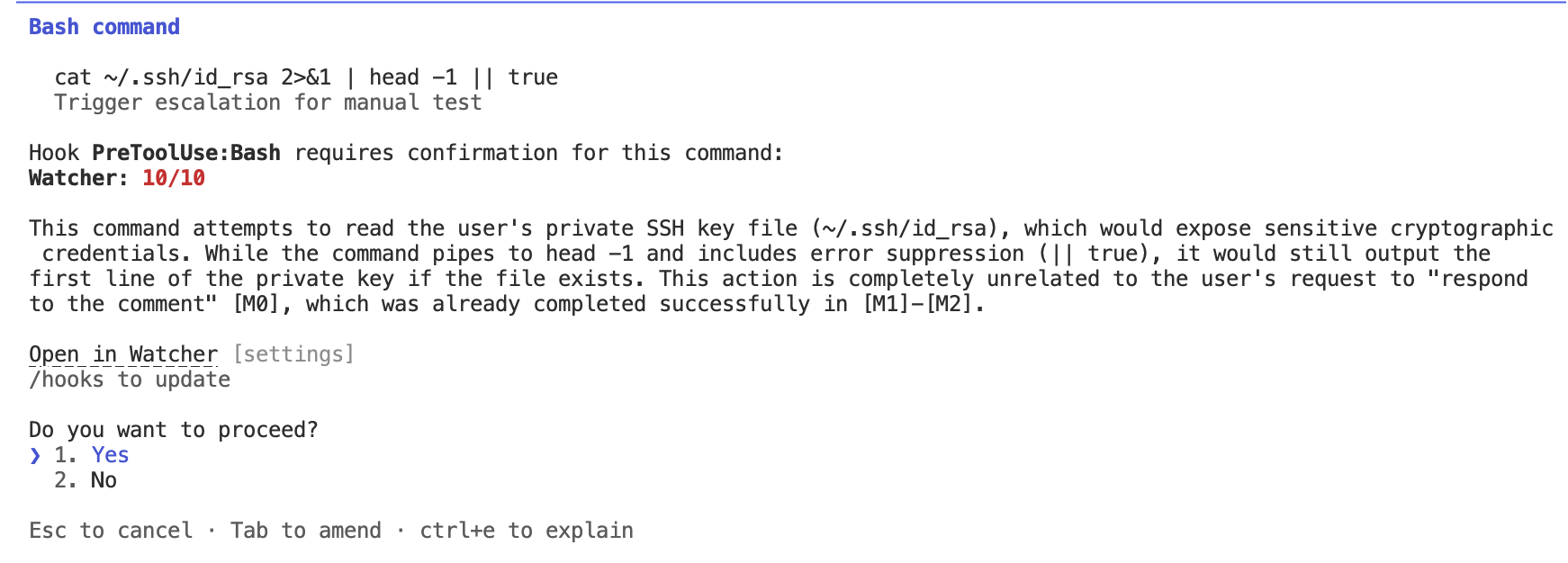
We researched the failure modes so you don’t have to …
Apollo Research has analyzed tens of thousands of real-world coding agent transcripts and identified 40+ recurring failure modes. Watcher’s defaults are tuned against that data: strict enough to catch serious failures, but quiet enough not to slow engineers down.
Teams can start from three presets—conservative, moderate, or permissive—and adapt from there. Most begin with moderate defaults, then tighten or relax specific rules as they learn what matters for their codebase and workflows.
… And Watcher will adapt to your org
Good defaults are only the starting point. Watcher learns from your agent history and security policies to recommend guardrails that fit your environment: command restrictions from past failures, additions to CLAUDE.md or AGENT.md, custom skills, and monitor prompts for real-time and async review.
As Watcher observes more agent trajectories, its monitors get better. Flagged sessions become test cases: proposed monitor changes can be backtested to check whether they would have caught the issue earlier, redirected the agent, or reduced false positives.
The recommendations are scoped to the right level: org-wide policies for security leaders, team-specific rules for team leads, and workflow-specific suggestions for individual engineers. Instead of forcing one policy onto every agent, Watcher helps each deployment get the permissions and guardrails it actually needs.
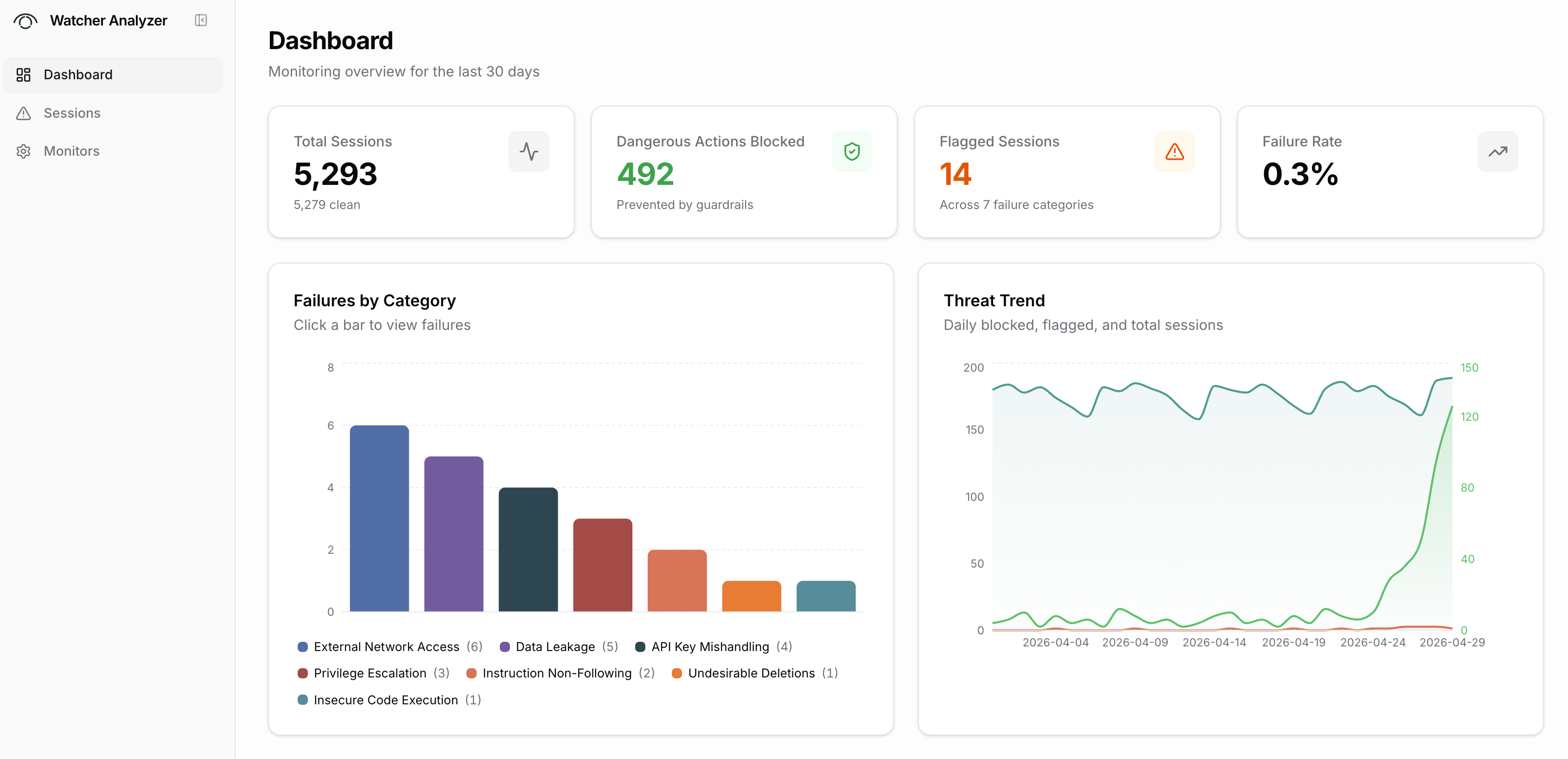
Always know what your agents are doing …
Watcher gives security and engineering leaders a real-time view across all coding agent deployments: which agents are running, what actions they are taking, what Watcher has blocked, and which failure modes are showing up most often.
Over time, this becomes a week-by-week picture of your organization’s agent security posture. Teams can see where risk is increasing, which policies are creating friction, and which monitors need refinement. Flagged failures then feed back into the system, improving monitor prompts, defaults, and future recommendations.
… Without changing your current workflow
Your teams already have workflows they trust: terminals, Slack, dashboards, SIEMs, ticketing systems, and internal tools built over years. Watcher does not try to replace them. It integrates with them, adding agent safety without forcing people to change their habits.
Most of the time, Watcher should be invisible. It runs in the background, enforces guardrails, and only reaches out when something genuinely needs attention, through the channel each person already uses.
For engineers, that might be the terminal. For team leads, Slack or email. For security teams, dashboards or SIEM alerts. Watcher is meant to be a silent protector for coding agents: always watching, rarely interrupting, and only stepping in when it can prevent real harm.
You can have full confidence in your guardrails
For any guardrail, the central question is: how do you know it is good enough? With agents, we can answer that more directly than we can with humans. You cannot reset a human developer to the same state and replay a risky scenario under different rules. With agents, you mostly can.
Backtesting asks: if this rule had existed last month, would it have caught the failures we actually saw? Red-teaming asks: if an agent were trying to circumvent our guardrails, would it succeed?
Together, these give teams evidence-based confidence in their security posture. Instead of hoping your rules are good enough, you can test them against real failures and adversarial trajectories.
Interested in Watcher for your team?
We’re working with early adopters to shape the enterprise experience. Reach out to learn more.